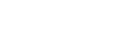
随着科技的不断发展,视频和声音技术在各个领域得到了广泛应用。其中,将语音转化为文字的技术成为了一种热门的研究方向。本文将介绍如何利用视频识别声音的方法,实现从视频中提取文字的功能。
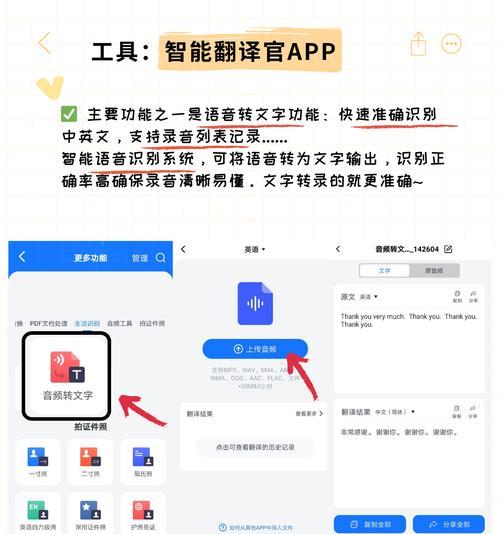
标题和
1.视频识别声音的意义和应用领域
视频识别声音作为一种新兴技术,在多个领域具有重要应用价值。例如,在教育领域,可以实现自动字幕生成和语音听写等功能;在媒体和广告领域,可以提高内容生产效率和用户体验。
2.视频处理和声音分析的基础知识
在了解视频识别声音的方法之前,需要了解一些基础知识,包括视频处理和声音分析等相关技术。视频处理主要涉及视频帧提取、特征提取和对象跟踪等;声音分析则包括语音识别、语音合成和语音情感分析等。
3.视频和声音数据的预处理方法
在视频识别声音之前,需要对视频和声音数据进行预处理,以提高后续的识别准确率。预处理方法包括视频去噪、音频滤波和声音增强等。
4.视频中声音的提取和分割技术
视频中的声音可能与背景音混合在一起,因此需要采用声音提取和分割技术,将目标声音从背景中提取出来。常用的技术包括盲源分离、时域分离和频域分离等。
5.声音特征提取和表示方法
声音特征提取是将声音信号转化为可计算的数值特征,以便后续的处理和分析。常用的声音特征包括时域特征、频域特征和时频特征等,表示方法包括MFCC和音素序列等。
6.语音识别的基本原理和方法
语音识别是视频识别声音的核心环节,它将声音信号转化为文字信息。基于统计模型的语音识别方法包括隐马尔可夫模型(HMM)和深度神经网络(DNN)等。
7.视频中文字的定位和检测技术
视频中的文字定位和检测是将识别到的声音对应到视频帧中的文字区域,并进行定位和检测。常用的方法包括文本检测和识别、OCR技术和目标检测等。
8.语音转文本的解码和后处理方法
语音转文本是将识别到的声音转化为可读的文本信息,解码和后处理方法用于提高识别准确率和语义连贯性。常用的方法包括N-gram语言模型和语义解码等。
9.视频中文字的校正和纠错技术
由于视频中的文字可能受到光照、噪声和运动模糊等干扰,因此需要进行文字校正和纠错。常用的技术包括文本校正、OCR纠错和文本规范化等。
10.视频识别声音的挑战和解决方案
视频识别声音虽然具有广阔的应用前景,但也面临一些挑战,如多说话人识别、噪声环境下的识别和口音识别等。针对这些挑战,可以采用深度学习模型、数据增强和模型融合等解决方案。
11.视频识别声音的性能评估方法
对于视频识别声音的方法,需要进行性能评估,以衡量识别准确率和效果。常用的评估指标包括准确率、召回率和F1值等。
12.视频识别声音的实践案例和应用场景
视频识别声音已经在多个应用场景中得到了实际应用。例如,在视频会议中自动转化为文字的功能、视频剪辑中的字幕生成和直播平台的语音识别等。
13.视频识别声音的发展趋势和前景展望
随着人工智能和大数据技术的不断发展,视频识别声音在未来将有更加广阔的应用前景。例如,结合自然语言处理和知识图谱等技术,可以实现更加智能化的视频识别声音。
14.视频识别声音的优势和局限性
视频识别声音作为一种新兴技术,具有一些明显的优势,如实时性和多模态融合等。然而,也存在一些局限性,如硬件设备要求和对语音质量的依赖等。
15.结论:视频识别声音的方法为从视频中提取文字提供了一种有效的途径,未来在多个领域具有广阔的应用前景。我们相信随着技术的不断进步,视频识别声音将会越来越成熟和普及,为人们的生活带来更多便利和效益。